simulia 最新发布的 abaqus 6.11 中加入了 gpu 加速 abaqus/standard 求解模块的功能,从而使用户在面临规模日益增长的计算模型时,abaqus 能够在并行计算的基础上,发挥 gpu 浮点计算的特长,进一步提高问题的求解效率。本文在上海超级计算中心“魔方”平台上通过 abaqus 6.11 求解典型结构力学问题,针对 abaqus/standard 求解模块的 gpu 加速性能进行了测试分析。
结果表明,在 cpu 并行规模小于 16 的情况下开启 gpu 加速后,多种类型结构问题的求解效率均有不同程度的提高,并且结构静力学与非滑移接触问题的加速效果最为明显,个别单元类型问题 gpu加速无法得以体现。随着 cpu与 gpu异构协同处理技术的不断发展,gpu 加速在 abaqus软件中必将发挥越来越重要的作用。
一、abaqus 与 gpu 通用计算简介
abaqus是ds simulia旗下一套功能强大的工程模拟有限元分析软件,可以分析复杂的固体力学结构力学系统,特别是能够驾驭非常庞大复杂的问题和模拟高度非线性问题,在大量的高科技产品研究中发挥着巨大的作用。abaqus中包含abaqus/standard 和abaqus/explicit两个主求解器模块,abaqus/standard提供并行稀疏矩阵求解器,对各种大规模计算问题都能十分可靠地快速求解。在解决实际问题时,计算规模往往非常庞大,除了强大的并行功能外,abaqus/standard还包含许多新颖的求解技巧来提高求解速度。dassault systèmes于 2011 年 5 月发布了最新版本abaqus 6.11,在最新版本中增加了gpu加速求解功能,能够利用英伟达。
目前,通用科学与工程计算正由cpu中央处理向cpu与gpu协同处理的方向发展。在abaqus/standard 6.11 中,cpu负责控制作业的启动和终止,gpu负责求解繁重的计算任务,并将结果通过pcie×16 接口返回给cpu。根据官方数据的quadro或tesla系列gpu,实现由gpu加速的cae计算。
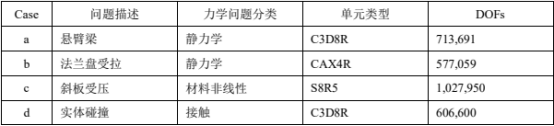
二、测试工况
本文选取结构静力学、材料非线性以及状态非线性(接触)三类典型结构问题,其中静力学
问题采用两种不同单元类型,设计四个测试工况,工况设置如表 1 所示。
表 1 测试工况表
典型的计算模型示意图如图 1 所示。
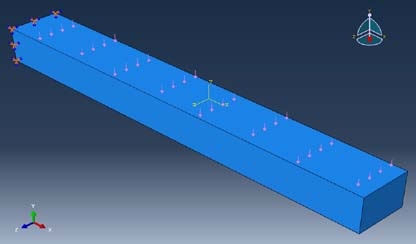
图 1 测试模型(case a)
在静力学问题求解过程中增量步与迭代步数目均为 1,非线性问题求解时的最大增量步长为0.2,在 20 个增量步之内完成。对每个模型首先在不同的并行规模下进行求解(cpu核心数分别为 2、4、8、16),记录下cpu求解所需时间tcpu,然后在abaqus/standard求解器中开启gpu加速选项,再针对同一问题进行求解,记录下带有gpu加速下的计算耗时tcpu gpu,并进行统计处理。
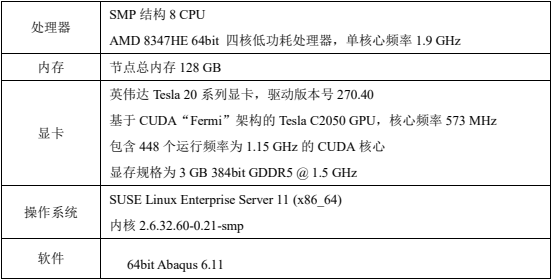
三、软硬件测试环境
abaqus/standard求解器模块的gpu加速性能测试在上海超级计算中心“魔方”超级计算机上完成。“魔方”(曙光 5000a)共包含 1450 个刀片节点、82 个胖节点、32 个普通接入节点以及8 个图形接入节点,内存总容量 95tb,磁盘总容量 500tb,采用infiniband互联方式。本次测试工作在gpu胖节点上进行。节点主要硬件配置如表 2 所示。
表 2 魔方 gpu 节点配置
四、测试结果分析
4.1、cpu 并行规模对 gpu 加速性能的影响
不同并行规模下abaqus/standard计算耗时典型测试结果如图 2 所示。通过对比可以发现,在case a中,gpu加速功能的开启能够明显提高求解效率,并且cpu并行规模越小,gpu加速的效果越理想,如在双核计算时,gpu加速能够将求解速度提高到 2.5 倍以上,加速效果相当可观,而当cpu并行规模增加至 16 核后,gpu参与求解与否对计算耗时的作用几乎可以忽略。出现这一现象的原因可能在于,随着并行规模的提高,单个cpu核心被分配的计算量迅速减少,从而令tcpu处于较低的水平,此时开启gpu加速功能后, cpu与gpu的计算量的分配工作本身亦需要消耗一定的资源,因此gpu的加速性能并不能得到很好的体现。类似的变化规律同样符合case c,并且在相同的并行规模下,gpu加速效果在case c中的作用相对而言有限得多,即使在最小的双核并行规模下,开启gpu加速也仅仅将计算耗时降低了 24%。

case a case c
图 2 典型工况计算耗时对比
4.2、结构问题类型对 gpu 加速性能的影响
图 3 为在并行规模为双核、4 核、8 核以及 16 核时,四组工况的gpu加速性能对比,图中以cpu计算耗时tcpu为基准,对gpu加速后的计算耗时tcpu gpu进行归一化处理,所占百分比在图中以数字标识。
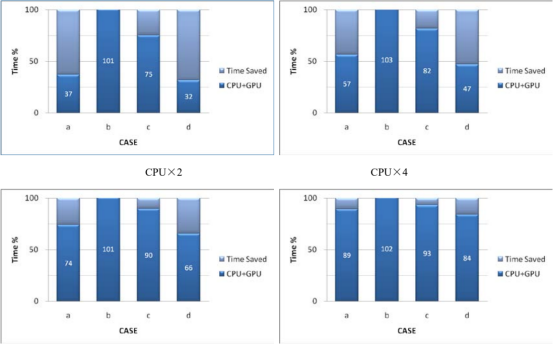
cpu×8 cpu×16
图 3 不同结构问题的 gpu 加速效果
从图 3 中可以看出,除case b外,其余三组工况中,无论是结构静力学问题(case a),还是材料非线性问题(case c),或者是状态非线性问题(case d),gpu对abaqus/standard求解器模块均有不同程度的加速作用,问题的求解时间均有不同程度的下降。其中,结构静力学问题与接触问题中的gpu加速性能体现得最为明显,如case d在 8 核并行规模下开启gpu加速能够减少计算耗时 30%以上。gpu对材料非线性问题的加速性能一般,求解时间至少为tcpu值得注意的是,在case b中,无论cpu并行规模大小,t的 75%以上。
cpu gpu全部高于tcpu,这就意味着,在abaqus/standard求解器中开启gpu加速选项,结果却使得最终求解时间不减反增。需要指出的是,case b与case a同属于结构静力学问题,计算量也相当,两者的差别主要在于单元类型不同,case a为实体单元,而case b则为轴对称平面单元,其结果却是gpu加速性能相差很大,由此推测,gpu对采用个别单元类型的结构静力学问题的加速作用并不能很好地得以体现,甚至将引起计算时间变长,但需要进一步的测试工作来验证。
五、结论
本文介绍了 abaqus 6.11 中新增的 gpu 加速功能,利用上海超级计算中心“魔方”超级计算机的 gpu 节点平台,通过典型结构问题的求解,分析结果表明:
(1)开启 abaqus/standard 6.11 中 gpu 加速功能,典型的一般静力学、材料非线性、接触类型问题的求解效率均有不同程度的提高,测试中最高能减少相同并行规模下的 cpu 求解时间的 68%,加速性能相当可观;
(2)随着 cpu 并行规模的增加,gpu 加速效应逐渐减弱;
(3)gpu 加速对结构静力学问题与接触问题效果最为明显,对材料非线性问题的加速性能一般,对个别单元类型问题 gpu 的加速性能有可能无法得以体现。
作为第一个支持 gpu 加速的版本,gpu 对 abaqus/standard 求解器模块的加速效果是有目共睹的。根据 simulia 规划,在 abaqus 未来版本中,更多模块的计算会迁移到 gpu 上运行,并进一步提供多 gpu 加速的支持,gpu 加速在 abaqus 中将起到举足轻重的作用。
资料来源:达索官方





















